Um dos usos mais frequentes do Power Automate é manipular textos e extrair dados para realizar tarefas. Com o Power Automate, é possível extrair texto de e-mails, PDFs, imagens, Excel ou Listas do SharePoint, entre muitas outras fontes.
No entanto, esses textos geralmente precisam de algum tratamento antes de serem utilizados. Neste artigo, você aprenderá como extrair textos específicos de strings com o Power Automate, combinando expressões avançadas que resultam em um output limpo (para aprender sobre como utilizar expressões em Power Automate, veja este artigo em inglês).
Variáveis de tipo string em Power Automate
Ao longo deste artigo, trabalharemos com variáveis. As variáveis são utilizadas para armazenar e manipular dados durante a execução de um fluxo, mantendo valores temporários (se você quiser saber mais sobre como trabalhar com variáveis no Power Automate, confira este artigo).
No Power Automate, cada variável tem um tipo de dado específico, o que significa que uma variável destinada a números não pode armazenar texto, e aquelas voltadas para valores booleanos não manipularão objetos (consulte este artigo para entender quais são os tipos de dados no Power Automate e como interagir com eles). Os valores de texto possuem o tipo de dado string, e ao longo deste post, usaremos as palavras “string” e “texto” de forma intercambiável.
Para os exemplos ao longo deste artigo, usaremos o seguinte texto, armazenado em uma variável do tipo string chamada ‘main_text’:
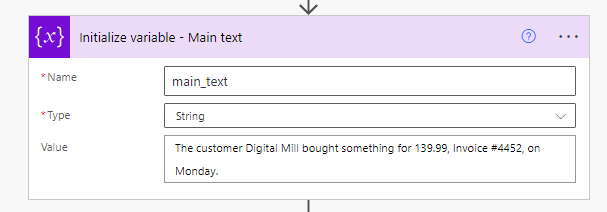
Aqui está o texto, caso você queira replicá-lo no seu ambiente:
The customer Digital Mill bought something for 139.99, Invoice #4452, on Monday.
Obtendo a quantidade de caracteres em um texto com Power Automate
Uma expressão muito útil no Power Automate é a length(), que retorna a quantidade de caracteres de uma string. Ela é ideal para tarefas como verificar números de documentos (como um CPF), códigos postais ou IDs de produtos. Além disso, é muito prática para definir limites de caracteres, seja para avaliações de produtos concisas ou entradas otimizadas para um modelo GPT da OpenAI.
A expressão length() requer um único parâmetro: o texto a ser verificado (a mesma expressão também pode contar elementos dentro de um array). Vamos usar a expressão para capturar o comprimento da variável ‘main_text’ e armazená-lo em outra variável chamada ‘text_length’, que deve ter o tipo de dado inteiro, já que essa expressão retorna um número inteiro:

A saída é a quantidade de caracteres no ‘main_text’, que é 80:

A expressão também funcionará para strings vazias, retornando o valor 0. Para identificar strings vazias, também é possível usar a expressão empty(), que retorna uma resposta booleana (verdadeira ou falsa). Assim como a expressão length(), a empty() requer apenas um parâmetro, que é o texto a ser verificado:

Como a variável ’empty_string’ não contém nenhum texto, o resultado da expressão empty() é verdadeiro:

Combinando dois textos com Power Automate
No Power Automate, você também pode combinar dois textos de forma fluida. Existem dois métodos para isso: um envolve o campo de input da ação diretamente, e o outro utiliza a expressão concat(). Por exemplo, se quisermos adicionar o texto “Desciption:” antes do conteúdo da variável ‘main_text’, podemos fazer isso inserindo o texto no input da ação seguido pelo conteúdo dinâmico de ‘main_text’ (destacado em amarelo), ou usando a expressão concat() (destacado em verde) e passando cada string como parâmetros para isso (primeiro parâmetro destacado em rosa e segundo em azul).

Como esperado, ambas as abordagens trazem o mesmo resultado:

Localizar texto dentro de uma string em Power Automate
Existem basicamente dois métodos para identificar se uma string contém um texto específico. Um deles é a expressão contains(), que retorna um valor verdadeiro ou falso indicando a presença do texto. A expressão requer dois parâmetros: primeiro, a string onde o texto será pesquisado; e segundo, o texto a ser buscado. Neste caso, testaremos se a palavra ‘invoice’ (destacada em verde) existe dentro da variável ‘main_text’ (destacada em amarelo).

Neste exemplo específico, o retorno da expressão contains() será falso, pois estamos procurando por ‘invoice’ (com ‘i’ minúsculo), enquanto a variável contém ‘Invoice’ com ‘I’ maiúsculo:

Para identificar um texto ignorando letras maiúsculas ou minúsculas, basta converter a string como um todo para letras minúsculas ou maiúsculas (exploraremos essa solução em mais detalhes em uma seção posterior).
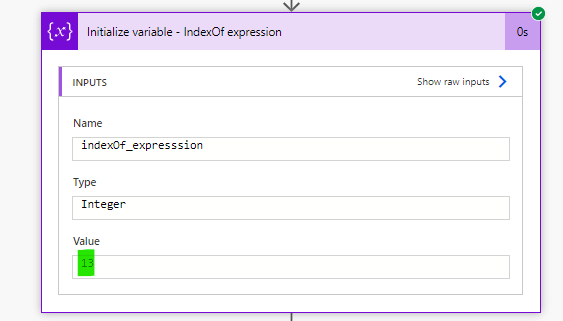
A outra estratégia para identificar textos dentro de strings é usar a expressão indexOf(). Semelhante ao contains(), essa expressão também exige dois parâmetros: a string na qual procuraremos um texto (neste caso, a variável “main_text”, destacada em amarelo) e o texto a ser buscado (neste caso, ‘Digital Mill’, destacado em verde):

Essa expressão retorna a posição do caractere onde um texto está localizado. No nosso exemplo, como o valor de retorno foi 13, o texto ‘Digital Mill’ pode ser encontrado no 14º caractere da nossa variável (como este valor é considerado “zero-indexed”, a sua contagem começa em zero):
Retornando parte de um texto baseada em sua posição com Power Automate
Existem duas expressões que permitem recuperar um texto com base nas posições dos caracteres dentro de uma string.
A expressão substring() recebe três parâmetros: a string de origem, a posição inicial para a extração e a quantidade de caracteres a serem extraídos. Aqui, usaremos a variável ‘main_text’ como origem (destacada em amarelo), definiremos o valor extraído no exemplo ‘indexOf’ como a posição de início (destacada em verde, armazenamos esse valor em uma variável chamada ‘indexOf_expression’) e definiremos a quantidade de caracteres a serem extraídos como 20 (destacada em azul):

O resultado será ‘Digital Mill bought ’ (com um espaço em branco no final). A expressão está capturando 20 caracteres a partir do 14º caractere da string. Embora o Power Automate use índices baseados em zero para contagem, outras operações numéricas geralmente começam no 1. Nesta expressão, o segundo parâmetro segue a convenção de indexação zero, enquanto o terceiro parâmetro não.

A outra expressão, slice(), realiza a extração de texto por posições de caracteres, semelhante a substring(). No entanto, slice() retorna um texto com base em uma posição inicial e final de caracteres. Ela também recebe três parâmetros: a string de origem, a posição inicial e a posição final do texto a ser extraído. No nosso caso, usaremos novamente a variável ‘main_text’ como origem (destacada em amarelo), definiremos o valor extraído no exemplo de ‘indexOf’ como a posição inicial (destacada em verde, armazenado em uma variável chamada ‘indexOf_expression’) e definiremos a posição final como 20 (destacada em azul):

Mesmo utilizando os mesmos parâmetros do ‘substring()’, o resultado é diferente: agora, não estamos capturando os 20 caracteres após o 14º, mas definindo a posição inicial e final (13º e 21º caracteres). O resultado é “Digital”:

Convertendo texto para letras minúsculas ou maiúsculas com Power Automate
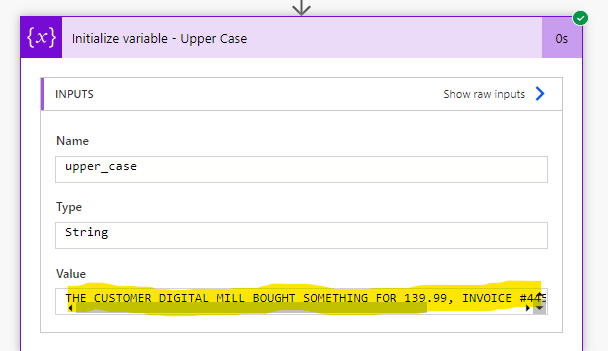
Uma boa prática ao extrair partes de um texto é padronizar o uso de letras maiúsculas ou minúsculas em toda a string. Isso é importante devido à sensibilidade de maiúsculas e minúsculas no Power Automate, onde “invoice” é considerado diferente de “Invoice”, como vimos em seções anteriores. Para converter um texto em letras maiúsculas ou minúsculas, podemos usar as expressões toUpper() e toLower(). Ambas as expressões recebem apenas um parâmetro, que é o texto a ser transformado. No exemplo abaixo, pretendemos transformar a string da variável ‘main_text’ em letras maiúsculas:

Este será o output:
Substituindo parte de uma string com Power Automate
Substituir textos dentro de uma string é uma tarefa fácil no Power Automate. Podemos usar a expressão replace(), que exige três parâmetros: o texto de origem, o texto a ser substituído e o novo texto. Para este exemplo, estamos usando a variável ‘main_text’ como string de origem (destacada em amarelo), ‘Monday’ como o texto a ser substituído (destacado em verde) e ‘Friday’ como o novo texto (destacado em azul):

Como resultado, teremos o texto original completo, mas com ‘Monday’ substituído por ‘Friday’:

Removendo espaços de um texto (trimming) no Power Automate
Ao limpar textos no Power Automate, a remoção de espaços em branco é uma das tarefas mais importantes. O processo de trimming remove todos os espaços em branco no início ou no final de um texto, mantendo apenas o conteúdo relevante. No Power Automate, essa tarefa pode ser executada com a expressão trim(), que requer apenas um parâmetro: o texto a ser limpo. No exemplo abaixo, temos espaços em branco no início do texto (destacado em amarelo), no meio (destacado em azul) e no final (destacado em verde):

Após executar o fluxo, apenas os espaços em branco do meio serão mantidos, uma vez que os espaços do início e do final são removidos pela expressão trim():

Transformando strings em arrays no Power Automate
A última expressão que vamos estudar neste artigo é a split(). Essa expressão transformará um texto em um array, o que às vezes pode ser útil para a transformação de textos. Essa expressão requer dois parâmetros: o texto a ser dividido e o separador a ser usado para a operação. No exemplo abaixo, estamos dividindo a variável ‘main_text’ por espaços em branco (destacados em amarelo), de modo que cada palavra se tornará um elemento do array (para aprender mais sobre arrays, consulte este artigo):

E este será o output:

Exercício: Isolando o número da fatura e o preço da variável ‘main_text’
Agora vamos praticar com um cenário de negócios comum: extrair partes específicas de um texto, que, neste caso, serão o número da fatura (invoice) e o preço da variável ‘main_text’. Precisaremos de uma variável para cada dado que queremos extrair, e elas terão algumas fórmulas aninhadas para alcançar o resultado desejado.
Apenas para lembrar, o texto armazenado na variável ‘main_text’ é o seguinte: “The customer Digital Mill bought something for 139.99, Invoice #4452, on Monday”.
Número de fatura (Invoice Number)
Como primeiro passo, precisamos identificar quais são os caracteres que estão ao redor do número da fatura (invoice), que neste caso são o “#” no início e uma vírgula no final. Como temos apenas uma ocorrência do caractere “#” em todo o texto, podemos começar por ele, usando a seguinte expressão para dividir o texto em duas partes: split(variables(‘main_text’), ‘#’).
Mas não precisaremos da primeira parte do texto (ou seja, tudo que está antes do “#”), então podemos adicionar um [1] ao final da expressão para acessar o segundo elemento do array gerado pela expressão split(): split(variables(‘main_text’), ‘#’)[1]. Lembre-se de que a contagem dos elementos do array é baseada em zero, então precisamos usar zero para acessar o primeiro elemento, 1 para acessar o segundo e assim por diante. Até este momento, o valor da nossa expressão é “4452, on Monday.”
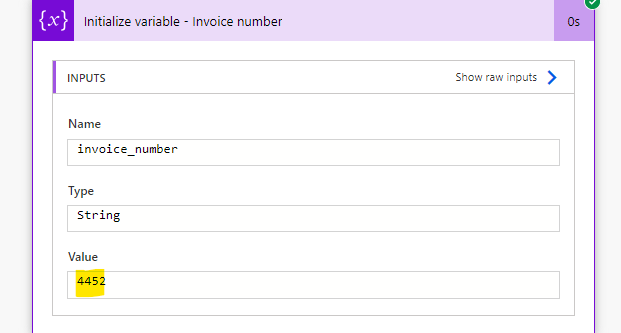
Agora repetiremos o mesmo processo, mas usando a vírgula como separador (temos apenas uma vírgula neste texto reduzido) e acessando o primeiro elemento do array gerado pela função split(). A expressão ficará assim: split(split(variables(‘main_text’), ‘#’)[1], ‘,’)[0]. Assim, atribuiremos essa expressão a uma variável:

O resultado será exatamente o número da fatura:
Preço (Price)
O processo para extrair o preço será muito semelhante, mas utilizando separadores diferentes. Primeiro, podemos dividir a variável ‘main_text’ por vírgulas, o que resultará em um array com três elementos (repare que o valor da fatura utiliza um ponto como separador de centavos). A expressão será split(variables(‘main_text’), ‘,’), e a saída ficará assim:
[
“The customer Digital Mill bought something for 139.99” ,
“Invoice #4452”,
“on Monday.”
]
Como queremos acessar o primeiro elemento do array, incluiremos um “[0]” no final da expressão, que ficará assim: split(variables(‘main_text’), ‘,’)[0]. O output será “O cliente Digital Mill comprou algo por 139.99”.
Agora precisamos dividir novamente, mas usando um espaço em branco como separador, o que resultará em um array com 8 elementos. Poderíamos apenas usar um “[7]” no final da expressão para acessar o elemento do preço, mas na verdade há uma maneira mais fácil que evitará a necessidade de contar os elementos: a expressão last(). Esta expressão retornará o último elemento de um array, independentemente da quantidade de itens. Portanto, nossa expressão final ficará assim: last(split(variables(‘main_text’), ‘,’)[0], ‘ ‘).
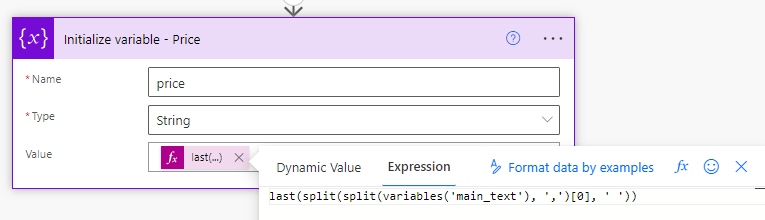
E este será o output:

Conclusão
Muitos problemas de negócios podem ser resolvidos usando expressões de texto. Embora possam parecer complexas no início, o tempo que gastamos para corrigir uma expressão pode resultar em horas de economia, evitando a necessidade de executar um processo de entrada de dados manualmente.
Agora que você sabe como usar expressões de texto, pense nas tarefas diárias que você pode delegar ao Power Automate!
